

Network monitoring protocols are the standardized industry conventions for acquiring data on the health and performance of the underlying network. They are extensively utilized by all network monitoring systems. In this blog, we aim to shed light on the mechanisms behind these protocols, hopefully without relying on excessive technical vocabulary.
What is Network monitoring?
Before delving into monitoring protocols, it's crucial to grasp the fundamental concepts of network monitoring best practices. It constitutes a broad technical expertise, and a single section within a post cannot offer a comprehensive introduction to the subject.
However, we have a dedicated blog post that precedes this one, providing a thorough introduction to the topic what is network monitoring.
And if you're still hungry for more information, we also recommend checking out our ebook titled Introduction to Network and IT Monitoring for Rookies.
The two well-known concepts in network monitoring are events and performance data. Although these are abstract data concepts, understanding how this information is technically transferred between devices and the monitoring system is crucial.
In general, there are two primary methods for acquiring data on events and performance:
- Using protocols
- Accessing data directly from devices or element managers
When we use the term 'protocol' in the context of monitoring, we are referring to a set of rules, standards, message formats, sequencing, and timing. These elements facilitate the exchange of information between devices and the monitoring system.
The other method of data transfer occurs when the monitoring system directly accesses data by utilizing Application Programming Interfaces (APIs) or accessing files or database records directly. We will explore these methods as well.
Common Network Monitoring Protocols
Now, let's explore the most prevalent network monitoring protocols one by one:
Ping
Ping (an acronym for Packet InterNet Groper) is one of the most fundamental methods of active monitoring.
It stands out as one of the most frequently employed monitoring techniques because of its simplicity in checking the vitality of a device. Now, here's the surprise: it's not a protocol; it's a method! Instead, it utilizes a traditional network layer protocol called ICMP (Internet Control Message Protocol), developed back in 1983.
Here's how it works: The monitoring system dispatches an ICMP message, known as Echo Request, to a device and patiently awaits a reply. This message is encapsulated in IPv4 or IPv6 packets, depending on the ICMP version of the protocol. If the device is operational, it will respond with an ICMP Echo Reply message, which the monitoring system receives. Upon receiving the reply, the monitoring system deduces that the device is functioning properly.
Of course, the monitoring system can also calculate the time between sending the request and receiving the response. This performance data indicates the total round-trip time, offering insights into the quality of the connection between the monitoring system and the device. Many monitoring setups rely on this method as the primary approach for generating alarms.
Ping is also the most accessible network management software utility, most likely already present on your PC. All it takes is opening the terminal (command) window and typing something like:
Give it a try! We hope the Ping explanation wasn't too painful, and that you still dare to read further.
SNMP (Simple Network Management Protocol)
SNMP is one of the oldest and most widely used network monitoring protocols. Even though SNMP is a management protocol and is intended to remotely manage (configure) devices, it is most often used for monitoring, both actively and passively.
When used for active monitoring, the monitoring system periodically sends a GET Request message to a device, and the device sends the data in the form of a GET Response message.
The data contained in the response represents the status of a device’s internal parameters. Therefore, the data received can be used for both performance data collection as well as to detect a faulty state of the device. For instance, if the variable indicating the state of the fan is 0 (not operating and not cooling the device), the monitoring system will automatically generate an alarm.
On the other hand, when passive monitoring is used, devices are configured to send event data to the monitoring system when something important has happened with the device. These messages are called traps. Traps indicating a significant change in a device’s operation are often mapped to alarms or alarm updates.
SNMP messages are being sent by a network protocol that does not guarantee delivery. This protocol is called UDP. Since UDP can’t guarantee delivery, the device that sent an important trap message can in no way know that the monitoring system ever received it. However, SNMP introduces “informs” (or strictly speaking “InformRequests”). A device can be configured to send informs instead of traps. When an important message must be sent, a device will send the same informs message until it receives an “I got it” message (acknowledgment response) back from the monitoring system.
All three methods can be combined for event and performance data collection. The figure below depicts an example in which devices 1 and 3 are being actively polled, while device 2 sends traps. Devices 4 and 5 are configured to send informs that must be acknowledged by the monitoring system.
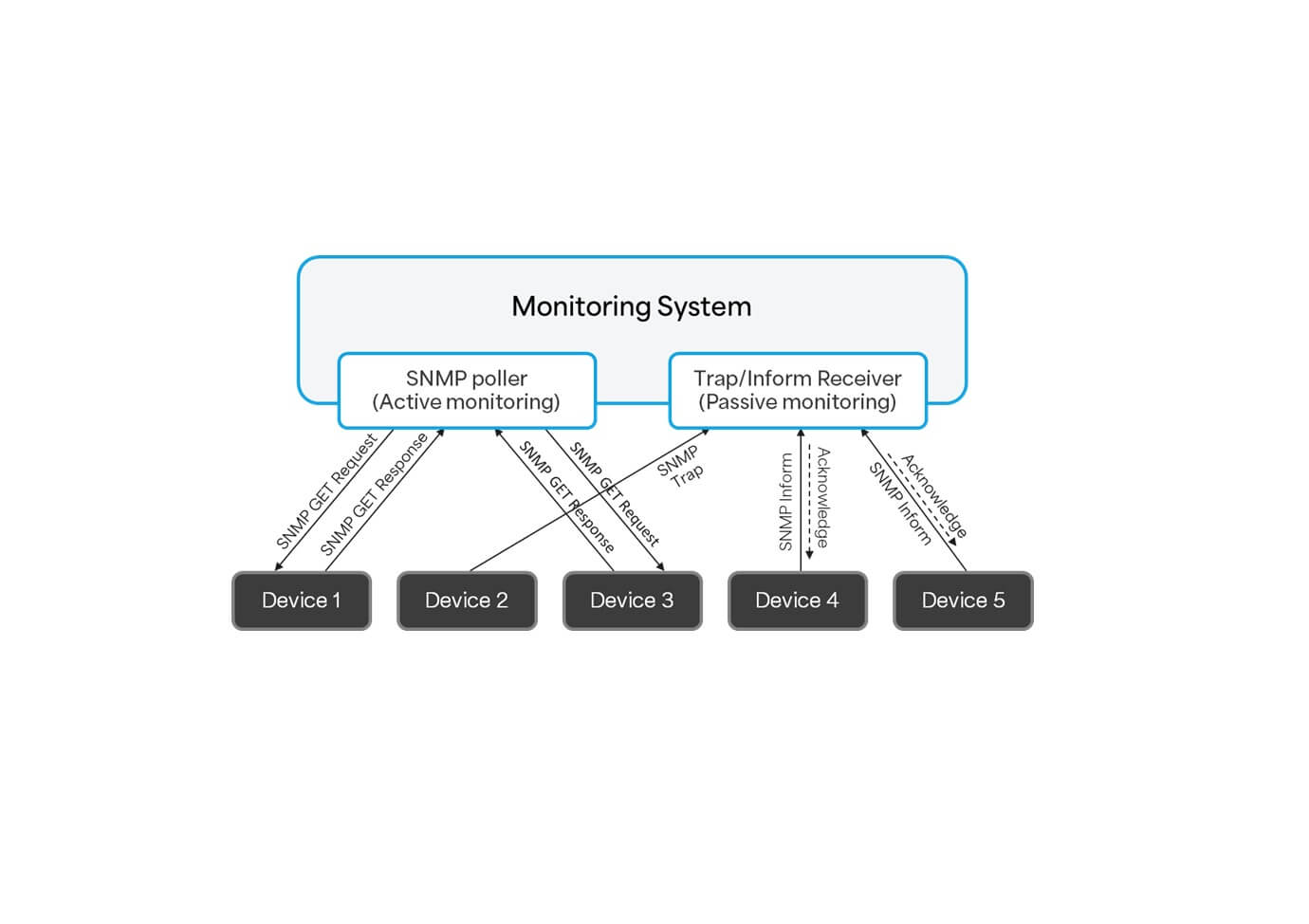
SNMP is a very old protocol, and it had two evolutionary steps. After version SNMP v1, the standard introduced SNMP v2c and SNMP v3, with each succeeding version introducing significant improvements to match the industry’s challenges. SNMP v1 was introduced in 1988, while version v3 was released in 2002.
Syslog
Syslog is a widely utilized protocol supported by a diverse range of network and IT devices. It is employed to transmit free text-formatted log messages to a central server.
All devices typically maintain their own logs, which can be regarded as free-text records generated with every event occurring on the device. These records may indicate changes in device configuration, alterations in port status, software errors, and more. Essentially, each log record corresponds to a specific event.
Syslog serves as the mechanism for devices to transmit these log records, representing events, as messages to the central log storage for network management purposes. Therefore, a syslog message arriving at the monitoring system on the central log server becomes a valuable source of event data. Through meticulous analysis of syslog messages, the monitoring system effortlessly identifies faults and associates them with alarms. Alongside Ping and SNMP, Syslog stands as one of the key mechanisms for acquiring event and performance data for monitoring.
The Syslog protocol was standardized in a recommendation RFC 5424. Syslog messages are sent via the UDP protocol, and syslog servers do not acknowledge the reception of messages, meaning delivery is not guaranteed. Despite its complex structure, the Syslog message comprises three major components: Facility, Severity level, and the Message itself. The Facility represents the code specifying the type of device sending the message, Severity describes the seriousness of the event (e.g., alert, critical, error, warning, etc.), and the Message is a structured field containing the log record, including the timestamp, hostname or IP address, and other relevant data.
While the syslog protocol is important from a monitoring perspective, the centralized log, created by aggregating logs from various devices, equips engineers with the ability to centrally manage, observe, and exercise analytic methods for a deeper insight into the network's behavior.
Read more about other benefits of network monitoring that engineers and businesses can expect.

Network Flows
There are specialized network management protocols for collecting data about network traffic flows. Put simply, a flow can be seen as a stream of IP packets between two points in the network.
More precisely (and apologies if this is too complex), a network flow is considered as a unidirectional sequence of packets that share the following characteristics: they all flow towards the same destination device interface, have the same source IP address and destination IP address, share the same IP protocol number (encapsulate the same transport-layer protocol), and have the same source and destination ports of UDP/TCP, as well as the same IP type of service.
Engineers observe flows to optimize network traffic, identify traffic flows causing excess traffic or congestion. Another valuable application is detecting security threats by analyzing flow patterns.
There are three well-established protocols that provide information about flows in the network:
- Cisco NetFlow
- sFlow (sampled flow, originally developed by InMon Corp)
- IPFIX (IETF Internet Protocol Flow Information Export)
Although the network monitoring protocols differ, they all provide flow data that can be used for alarm and performance data collection. The sources of flow data are network devices that support one of the network flow protocols or even active tap probes that provide live data without influencing normal network operation.
Other Sources of Event and Performance Data
As mentioned in the introduction, network monitoring protocols are only one way of collecting event and performance data. However, there are many other methods to fetch the data for all types of network monitoring.
When we use the term "fetch," we are referring to the acquisition of data from devices, servers, element managers, and so on. For example, one can utilize standard Application Programming Interface (API) calls or employ a simple file transfer and its subsequent analysis (parsing) to extract event and performance data.
One increasingly prominent method of receiving data is through streaming data via the, say, Apache Kafka bus. However, this is a specialized topic that we will address in one of our future blog posts. Now, let's discuss the typical sources of data for events and performance data.
Log Files
One very popular method of obtaining event data is by directly reading log files generated by a device. One way to do this is by directly connecting to the device and retrieving log file data. Another way is by transferring log files to the monitoring system file system and then accessing log file contents from there.
Either way, log records represent events that can be mapped to alarms when the record describes a faulty situation or a change of a faulty situation.

Specialized probes
Many vendors provide an active network performance probing mechanism that continually measures important aspects of the network such as:
- Jitter
- Response time
- Packet loss
- Voice Quality Scoring (MOS)
- Connectivity
- Server or website responses and downtime
- Delay
These probes can be specialized pieces of code running on network devices and they collect the data mentioned before, or probes can be specialized pieces of hardware doing performance data collection by tapping into the network.
In both cases, the data is collected by the monitoring system and used for generating alarms and performance data analysis. The method of collecting data can be via SNMP or any other method.
Event log
This is a Microsoft Windows OS specific log file. It contains OS messages about system, security, and applications events. A specific combination of EventID, category, and so on, may indicate a faulty situation and the monitoring system can use these to raise an alarm.
WMI
This acronym stands for Windows Management Instrumentation. It’s a Windows OS-specific scripting language that collects and provides information about the system in a Microsoft environment.
Element management systems & Platforms
Element management systems are a great source of standardized and vendor-specific data. The same applies to different platforms such as virtualization platforms or cloud platforms (AWS, Azure).
The way data is retrieved for both monitoring and discovery purposes vary. Some element managers can send SNMP traps/informs to the monitoring system or they can even be polled for data. Others will provide some sort of API (Application Programming Interface) which can be REST API, TM Forum OpenAPI, SOAP, CORBA or even files (e.g., log files) that contain the data.
In the case of an API, the monitoring system must have a plug-in (a piece of a specialized code) that will connect to the API and retrieve the data. The same API can usually be used to retrieve inventory data.
There are hundreds of element managers. Here are just some of them so you can get the general idea:
- Nokia Access Management System (AMS): an element management system for Intelligent Services Access Manager (ISAM) broadband access nodes
- Ericsson ENM: an element manager specialized for mobile network management
- Ericsson NetOp EMS: an element management system for the management of IP Networks
- Huawei iManager U2000/U2020: centrally manages Huawei mobile network elements
- Huawei NCE: centrally manages Huawei GPON network (among many other things)
- ZTE NetNumen U31: a family of element managers to manage ZTE’s network elements
- ADVA Ensemble Controller: an ADVA DWDM-specific EMS
On the other hand, there are many different service platforms that must be monitored, each providing its own API to access critical fault and performance data:
- VMware vCenter Server: an advanced server management software that provides a centralized platform for controlling virtualization platforms of VMware
- Amazon Elastic Compute Cloud (EC2): the platform provides an API to manage AWS services
- Microsoft Azure Cloud Services: the platform provides an API to manage Azure services
- Microsoft Hyper-V: monitoring of this platform is executed by use of data provided by a component “WMI provider” or by use of other specialized Microsoft software such as SCOM
There are many other specific sources of event and performance data, but any such source, before contributing to any monitoring activity, must be made accessible and interpretable by the monitoring system.

UMBOSS & Network Monitoring
One of the key roles of UMBOSS is umbrella network monitoring. As an umbrella platform, UMBOSS is designed to consolidate health and performance data from all sources in the network. This means that any protocol can be used, along with any logs, probe data, and any element manager to collect events and performance data.
One of the key advantages of having an umbrella system like UMBOSS in place is that you get a holistic view of the health and performance of the entire network. This is the only way you can learn about how the performance of one domain or part of the network influences the others. You can deploy complex alarm correlation across domains to detect alarms from seemingly unrelated events and also properly execute advanced analytic functions like root cause analysis (RCA), which can deduce the root cause by consolidating alarms from different domains of your system.
Have any questions about protocols or networking monitoring? Ask away! Drop us a message or book a demo so we can connect.








